
- Stricter controls for the Darwin Core occurrenceID to improve stability of record level identifiers network wide
- Ability to support Microsoft Excel spreadsheets natively
- Japanese translation thanks to Dr. Yukiko Yamazaki from the National Institute of Genetics (NIG) in Japan
The most significant new feature that has been added in this release is the ability to validate that each record within an Occurrence dataset has a unique identifier. If any missing or duplicate identifiers are found, publishing fails, and the problem records are logged in the publication report.
This new feature will support data publishers who use the Darwin Core term occurrenceID to uniquely identify their occurrence records. The change is intended to make it easier to link to records as they propagate throughout the network, simplifying the mechanism to cross reference databases and potentially help towards tracking use.
Previously, GBIF has asked publishers to use the three Darwin Core terms: institutionCode, collectionCode, and catalogNumber to uniquely identify their occurrence records. This triplet style identifier will continue to be accepted, however, it is notoriously unstable since the codes are prone to change and in many cases are meaningless for datasets originating from outside of the museum collections community. For this reason, GBIF is adopting the recommendations coming from the IPT user community and recommending the use of occurrenceID instead.
Best practices for creating an occurrenceID are that they (a) must be unique within the dataset, (b) should remain stable over time, and (c) should be globally unique wherever possible. By taking advantage of the IPT’s built-in identifier validation, publishers will automatically satisfy the first condition.
Ultimately, GBIF hopes that by transitioning to more widespread use of stable occurrenceIDs, the following goals can be realized:
- GBIF can begin to resolve occurrence records using an occurrenceID. This resolution service could also help check whether identifiers are globally unique or not.
- GBIF’s own occurrence identifiers will become inherently more stable as well.
- GBIF can sustain more reliable cross-linkages to its records from other databases (e.g. GenBank).
- Record-level citation can be made possible, enhancing attribution and the ability to track data usage.
- It will be possible to consider tracking annotations and changes to a record over time.
The IPT 2.1 also includes support for uploading Excel files as data sources.
Another enhancement is that the interface has been translated into Japanese. GBIF offer their sincere thanks to Dr. Yukiko Yamazaki from the National Institute of Genetics (NIG) in Japan for this extraordinary effort.
In the 11 months since version 2.0.5 was released, a total of 11 enhancements have been added, and 38 bugs have been squashed. So what else has been fixed?
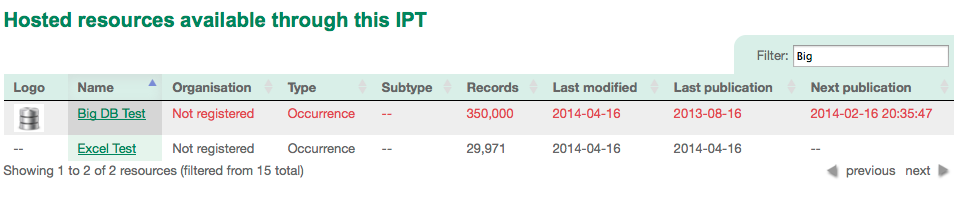
If you like the IPT’s auto publishing feature, you will be happy to know the bug causing the temporary directory to grow until disk space was exhausted has now been fixed. Resources that are configured to auto publish, but fail to be published for whatever reason, are now easily identifiable within the resource tables as shown:
If you ever created a data source by connecting directly to a database like MySQL, you may have noticed an error that caused datasets to truncate unexpectedly upon encountering a row with bad data. Thanks to a patch from Paul Morris (Harvard University Herbaria) bad rows now get skipped and reported to the user without skipping subsequent rows of data.
As always we’d like to give special thanks to the other volunteers who contributed to making this version a reality:
As always we’d like to give special thanks to the other volunteers who contributed to making this version a reality:
- Marie-Elise Lecoq, and Gallien Labeyrie (GBIF France) - Updating French translation
- Yu-Huang Wang (TaiBIF, Taiwan) - Updating Traditional Chinese translation
- Nestor Beltran (Colombian Biodiversity Information System (SiB)) - Updating Spanish translation
- Etienne Cartolano, Allan Koch Veiga, and Antonio Mauro Saraiva (Universidade de São Paulo, Research Center on Biodiversity and Computing) - Updating Portuguese translation
- Carlos Cubillos (Colombian Biodiversity Information System (SiB)) - Contributing style improvements

